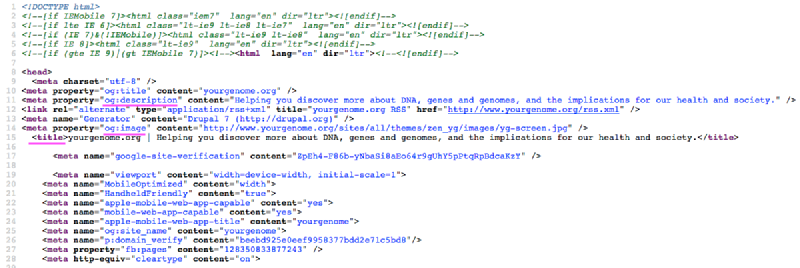
(Above image shows partial Page Source of “yourgenome.org”. Click here to see larger image.)
The following script can be used to get meta information (e.g., Title, Description, Image) from the provided url webpage, using RegExp instead of BeautifulSoup.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#! /usr/bin/env python
## usage: python url_meta.py URL
import sys
import re
import urllib2
user_agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_4; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.63 Safari/534.3'
headers = { 'User-Agent' : user_agent }
url = sys.argv[1]
req = urllib2.Request(url, None, headers)
response = urllib2.urlopen(req)
p_content = response.read()
response.close()
t_regexp = "<title>(.+?)</title>"
p_title = re.compile(t_regexp)
d_regexp = "<meta property=\"og:description\" content=(.+?)/?>"
p_description = re.compile(d_regexp)
img_regexp = "<meta property=\"og:image\" content=(.+?)/?>"
p_image = re.compile(img_regexp)
if p_title.search(p_content) != None:
print("title = " + "\"" + p_title.search(p_content).group(1) + "\"")
else:
print("title = " + "\" " + "\"")
if p_description.search(p_content) != None:
print("description = " + p_description.search(p_content).group(1))
else:
print("description = " + "\" " + "\"")
if p_image.search(p_content) != None:
print("image = " + p_image.search(p_content).group(1))
else:
print("image = " + "\"/images/*.png" + "\"")
print("url = " + "\"" + url + "\"")
|
Let’s do a test with YourGenome.org homepage:
python url_meta.py https://www.yourgenome.org
Which gives the result:
1
2
3
4
|
title = "yourgenome.org | Helping you discover more about DNA, genes and genomes, and the implications for our health and society."
description = "Helping you discover more about DNA, genes and genomes, and the implications for our health and society."
image = "https://www.yourgenome.org/sites/all/themes/zen_yg/images/yg-screen.jpg"
url = "https://www.yourgenome.org"
|
RegExp can be adapted to get other information from the webpage, e.g., content between specific tags “<>”.
{kind=link}