(标题图片来源:DZone.com)
机器学习三大类型
- 监督式学习 (Supervised Learning)
- 非监督式学习 (Unsupervised Learning)
- 强化学习 (Reinforcement Learning)
常用的机器学习算法
- 线性回归 (Linear Regression)
- 逻辑回归 (Logistic Regression)
- 决策树 (Decision Tree)
- 支持向量机 (SVM: Support Vector Machine)
- 朴素贝叶斯 (Naive Bayes)
- K最近邻算法 (KNN: K-Nearest Neighbors)
- K均值算法 (K-Means)
- 随机森林算法 (Random Forest)
- 降维算法 (Dimensionality Reduction Algorithms)
- Gradient Boost 和 Adaboost (梯度增强和自适应增强)
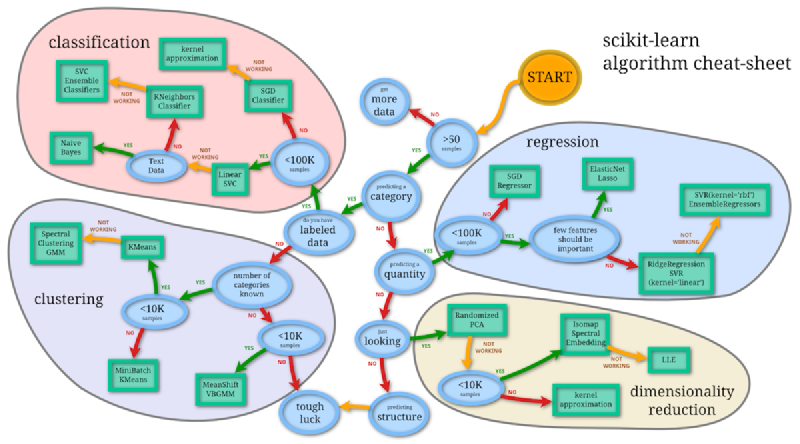
scikit-learn机器学习一例
scikit-learn最简单的安装是从conda (Anaconda或MiniConda),一并安装numpy, scipy, matplotlib等等。
第一次学习先避开经典的Iris Flower Dataset (安德森鸢尾花卉数据集? 拗口的中文名称),从简单的“苹果还是桔子?”开始:
你有一系列数据集描述苹果和桔子的数据特征(features),例如重量和粗糙度,让sklearn预测目标物是苹果还是桔子(label)?
使用scikit-learn的决策树
|
|
预测结果:
['Apple']
sklearn的更多算法使用可以参考Scikit-learn recipes 。
参考资料:
- [Essentials of Machine Learning Algorithms](Essentials of Machine Learning Algorithms) (中文)
- Machine Learning with Josh Gordon
免费教程:
- 12+ Hours Machine Learning in Python Course (Springboard.com)